





Interaction-Oriented
Cognitive Architecture
The behavior of our robot Golem-II+ is regulated by an Interaction Oriented Cognitive Architecture (IOCA). A diagram of IOCA can be seen next:
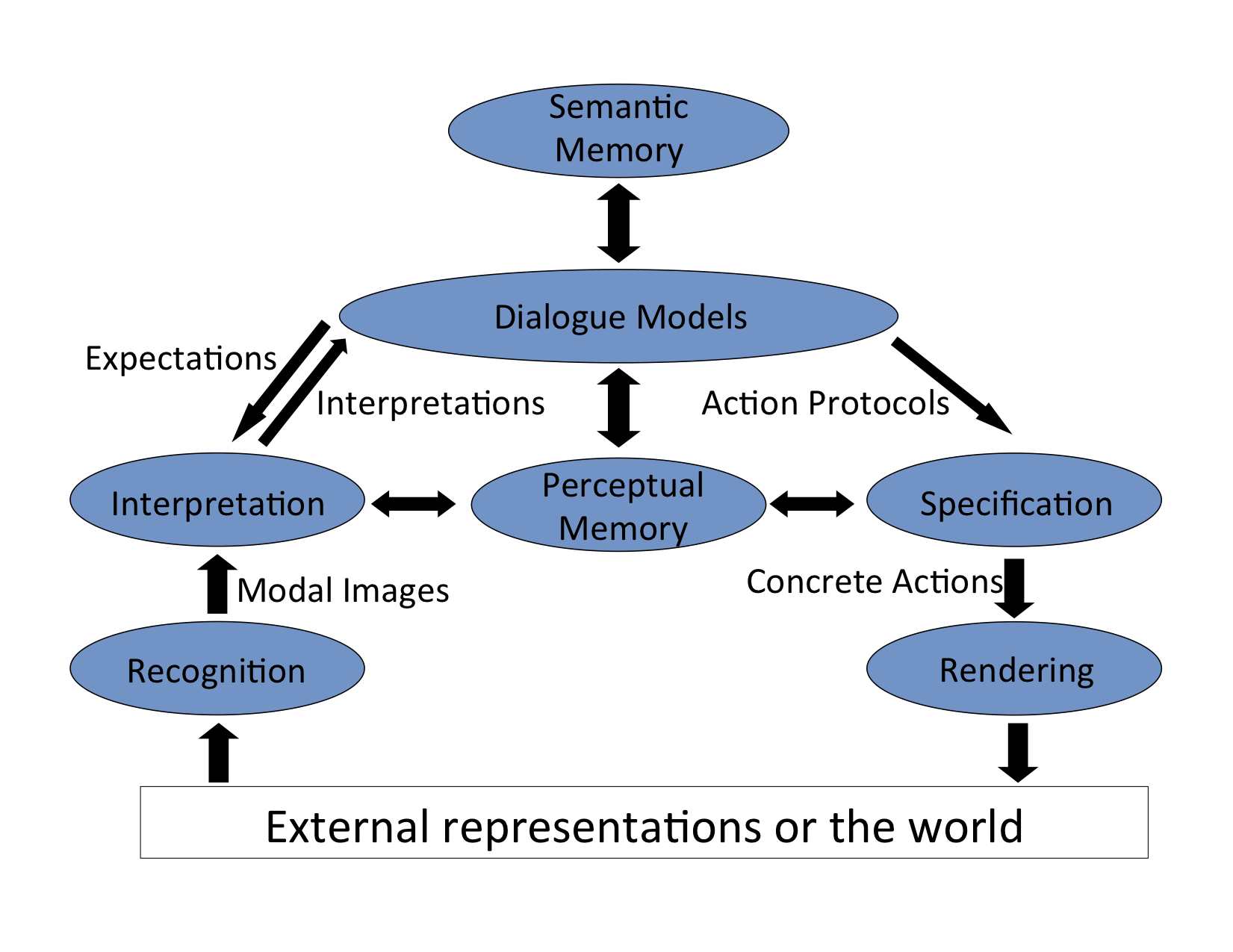
External stimuli (vision, audio, etc.) are processed by Recognition modules. There are different modules for different perceptual modalities. An example of a recognition module is the speech recognition module which encodes “raw” information (audio signal), but does not assign any meaning to it. We called the different encodings the Modalities of the system, while the Modal Image is an encoding of the recognized external acoustic or visual form. The Interpretation module assigns meaning to Modal Images. In order to do this, it takes into account the Expectations from the current situation and the history of the interaction. The Interpretation module has access to the Perceptual Memory which relates Modal Images with their meaning. These can be used to build the interpretation. Interpretations are represented in a propositional format, which is modality independent. For example, the same Interpretation can be acquired by speech recognition or by hand gesture recognition.
The Dialoge Models are the center of IOCA and have been the research focus of our group. Dialogue Models describe the task via a set of situations. A Situation is an information state defined in terms of the Expectations of the agent in the state, so if the Expectations change, the agent moves to a new Situation. Expectations depend on the context and can be determined dynamically in relation to the interaction history. The way that these Situations are linked together is by relating such Expectations with a corresponding Action and a following Situation. Expectations are propositional as well, and in order to be triggered they must be matched with an Interpretation. Once this matching occurs, the corresponding actions are performed and the system reaches its next Situation. Actions can be external (e.g. say something, move, etc.) or internal (e.g. plan, reason, etc.). Actions are composite roughly along the lines of Rhetorical Structure Theory (RST) and they involve more than one device. Actions are processed by the Specification modules considering the Perceptual Memory—producing a parametric specification of Concrete Actions. These are delivered to different Rendering devices, which produce changes in the state of the world.
An important part of IOCA is that the Dialogue Models perceive and interact with the world in an abstract manner. The state of the world and the set of possible expectations that can follow are given an abstract meaning, which, in reality, could have been perceived by any number of Recognizers. The same applies when acting upon the world: “going to the kitchen” is all that the Dialogue Model needs to state for the robot to start moving. This paradigm provides great flexibility in software development, as the Recognizers and Renderers become modular and replaceable, while the task description remains intact. This also secures a framework with which different tasks can be described and that does not require a complete rewrite of the internal software. Moreover, since the Recognizers and Renderers are modular, they can also be reused for different tasks with relative ease.