





Arquitectura orientada a la
interacción cognitiva
El comportamiento de nuestro robot, Golem-II+, es regulado por una Arquitectura Orientada a la Interacción Cognitiva (IOCA, por sus siglas en inglés). Un diagrama de IOCA se puede ver a continuación:
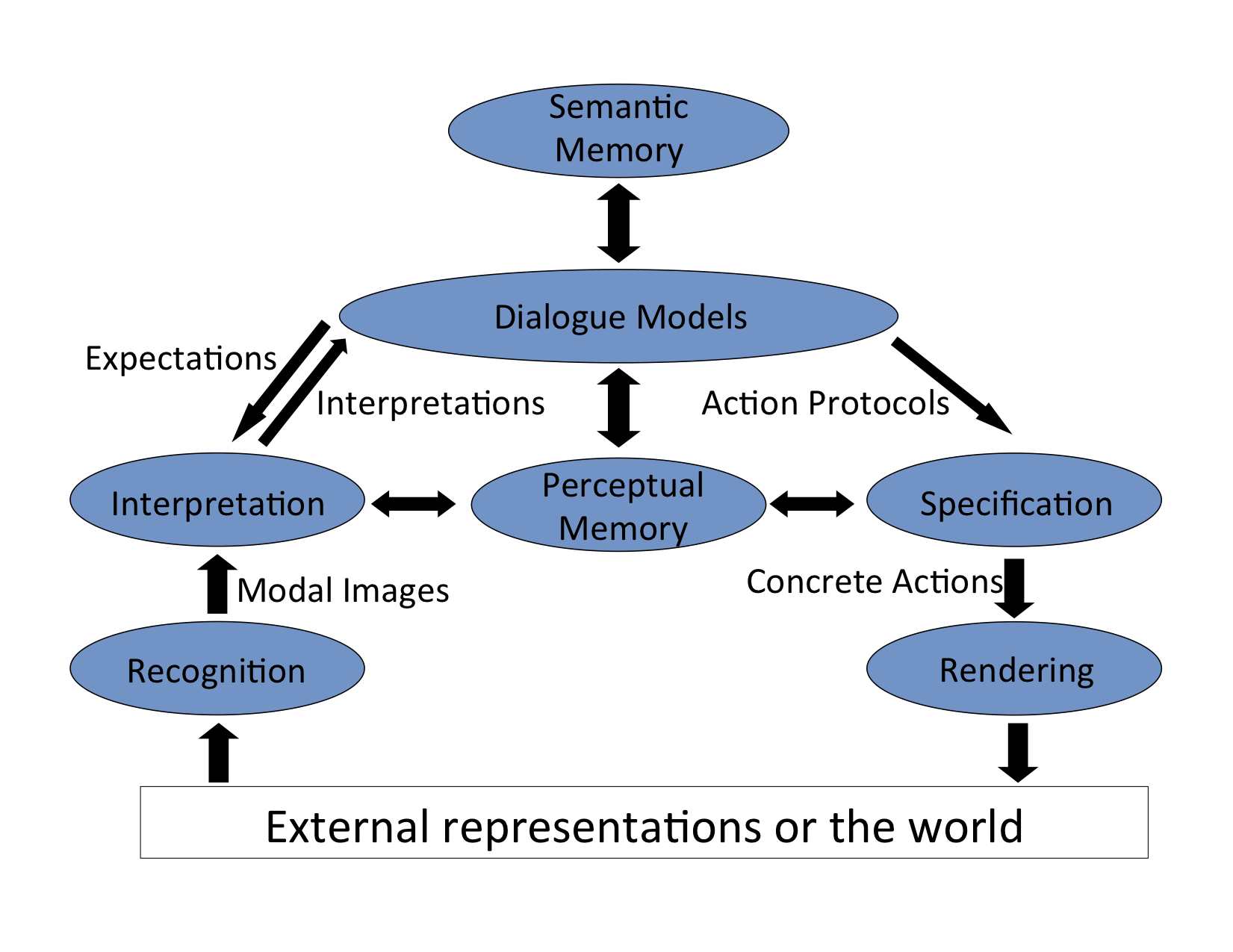
Estímulos externos (visión, sonido, etc) son procesados por los módulos de reconocimiento. Hay diferentes módulos para diferentes modalidades de percepción. Un ejemplo de un módulo de reconocimiento es el del habla, módulo de reconocimiento que codifica información bruta (señal de audio), pero no asigna ningún significado. Llamamos a las diferentes codificaciones las modalidades del sistema, mientras que, la imagen modal es una codificación del reconocimiento de formas externas acústicas o visuales. El módulo de Interpretación asigna significado a las imágenes modales. Con el fin de hacer esto, se tienen en cuenta las expectativas de la situación actual y la historia de la interacción. El módulo de Interpretación tiene acceso a la Memoria de percepción que asocia imágenes modales con su significado. Estos pueden ser usados para construir la interpretación. Las interpretaciones están representadas en un formato proposicional, que es una modalidad independiente. Por ejemplo, la interpretación misma puede ser adquirida por el reconocimiento de voz o con algún otro tipo de reconocimiento.
Los modelos de diálogo son el centro de IOCA y han sido el centro de investigación de este grupo. Los modelos de diálogo describen la tarea a través de un conjunto de situaciones. Una situación es la información de estado definido en términos de las expectativas del agente en dicho estado, si cambian dichas expectativas el agente se mueve a una nueva situación. Las expectativas dependen del contexto y se puede determinar dinámicamente en relación a la historia de la interacción. La forma en que estas situaciones están unidas entre sí es relacionando tales expectativas con su correspondiente acción y una situación siguiente. Las expectativas son también proposicionales y, con el fin de ser activado, se debe corresponder con una interpretación. Una vez que esta coincidencia se produce, las acciones correspondientes se llevan a cabo y el sistema alcanza la siguiente situación. Las acciones pueden ser externas (por ejemplo, decir algo, moverse, etc.) o un plan interno (por ejemplo planear, razónar, etc.) Las acciones son compuestas a lo largo de las líneas de la Teoría de la Estructura Retórica (RST) e involucra más de un dispositivo. Las acciones son procesadas por los módulos de especificación teniendo en cuenta la producción de memoria perceptual, una especificación paramétrica de acciones concretas. Estos se entregan a los diferentes dispositivos de representación, que producen cambios en el estado del mundo.
Una parte importante de IOCA es que los modelos de diálogo perciben e interactúan con el mundo de una manera abstracta. Se da un significado abstracto al estado del mundo y al conjunto de expectativas posibles que pueden seguir, que, en realidad, podría haber sido percibidas por cualquier número de reconocedores. Lo mismo se aplica al actuar sobre el mundo: "ir a la cocina" es todo lo que el modelo de diálogo necesita como argumento para que el robot comience a moverse. Este paradigma ofrece gran flexibilidad en el desarrollo de software, así los reconocedores y representadores se vuelven remplazables y modulares, mientras que la descripción de la tarea permanece intacta. Esto también asegura un marco con las diferentes tareas que se pueden describir y que no requiere de una reescritura completa del software interno. Por otra parte, dado que los reconocedores y representadores son modulares, también se puede reutilizar para diferentes tareas con relativa facilidad.